Overview
- Disney Research Studios is a research lab focusing on advancing storytelling through innovations in natural language processing, human-computer interaction, computer graphics, and robotics.
- When starting my master’s thesis at DRS, my goal was to make natural language generation more controllable (particularly large language models).
- To do so, I developed a system that allows AI characters to remember and recall events from previous conversations, marking a crucial step towards character consistency and more natural human-AI interaction.
- My research, making language generation more controllable, resulted in a U.S patent application, a peer-reviewed paper published at INLG 2023, and a 6/6 grade.
Context
- 🗓️ Timeline: 02/2023 — 09/2023
- 🏢 Company: DisneyResearch|Studios and ETH Zurich
- 👔 Role: Master’s Thesis Student (Computer Science)
- 📄 Paper: https://aclanthology.org/2023.inlg-main.17/
- ⚖️ Note: All resources not mentioned in the paper are protected by an NDA, meaning I cannot comment on them or make them available.
Technologies/Keywords
- Python
- Flask
- TypeScript
- Vue.js
- Docker
- Large language models (LLMs)
- Retrieval-augmented generation (RAG),
- Vector search
- LLM controllability
- Dialog systems
- Conversational AI
Details and Impressions
This project is one part of my master’s thesis at DisneyResearch|Studios and ETH Zurich. While the majority of the thesis is protected by an NDA, I can share details about the part of the project that we published in the paper linked above.
In short, the paper presents a system that can simulate virtual characters (e.g., a virtual Sherlock Holmes), allowing users to chat with them. In this post I will quickly go over some of the main points. To get you up to speed, this is the abstract of our paper:
In this paper, we present a system for augmenting virtual AI characters with long-term memory, enabling them to remember facts about themselves, their world, and past experiences. We propose a memory-creation pipeline that converts raw text into condensed memories and a memory-retrieval system that utilizes these memories to generate character responses. Using a fact-checking pipeline based on GPT-4 (OpenAI), our evaluation demonstrates that the character responses are grounded in the retrieved memories and maintain factual accuracy. We discuss the implications of our system for creating engaging and consistent virtual characters and highlight areas for future research, including large language model (LLM) guardrailing and virtual character personality development.
The character responses generated by the system are grounded in long-term memories, which are condensed versions of past interactions. Furthermore, depending on the situation, different response generators are chosen. For example, if the user asks the virtual character an off-topic question—e.g., about modern day politics—the system will create an evasive response. To provide some context, this is not reliably possible when solely relying on prompt engineering (as of Sept. 2023).
The following is a high-level overview of the system architecture:
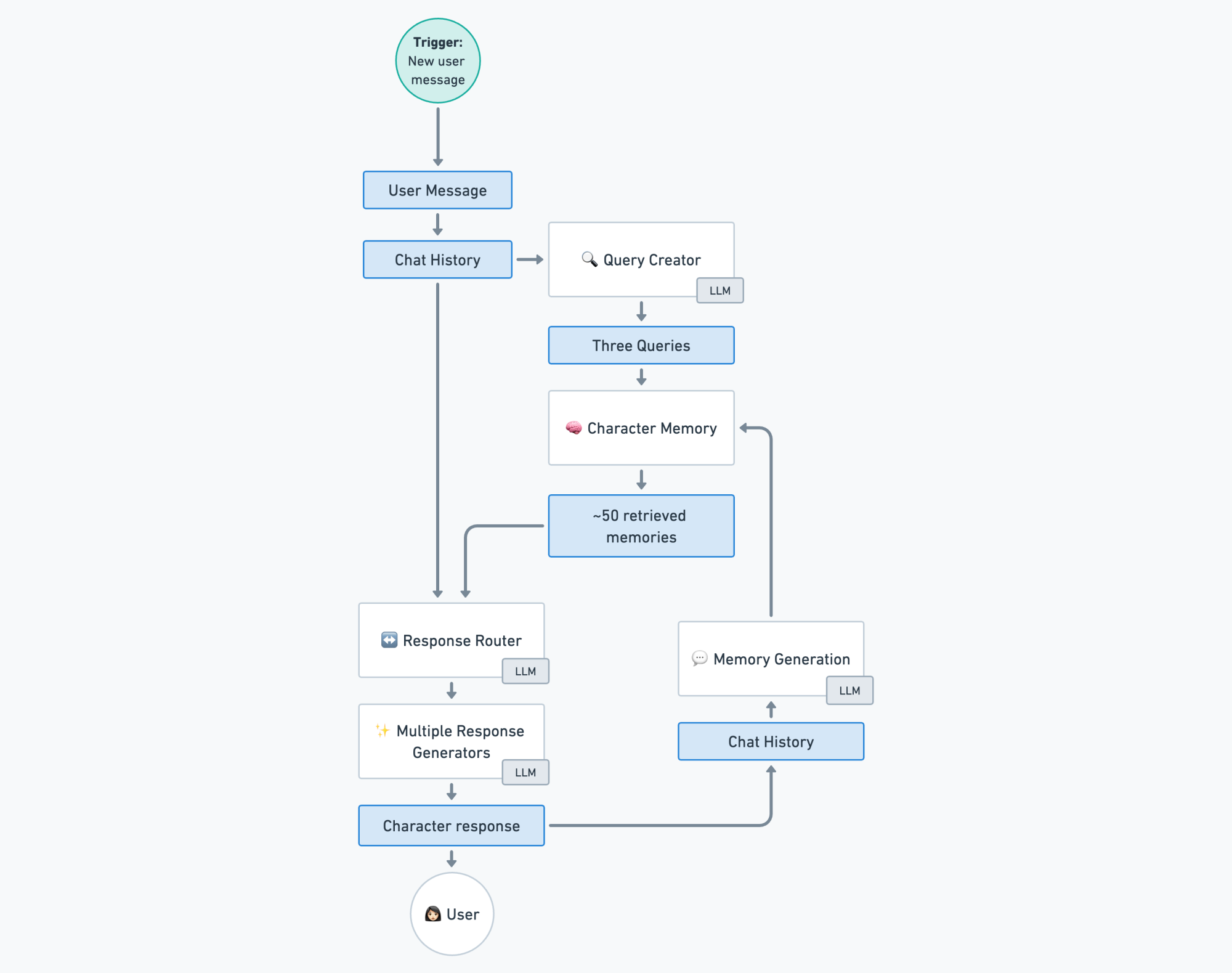
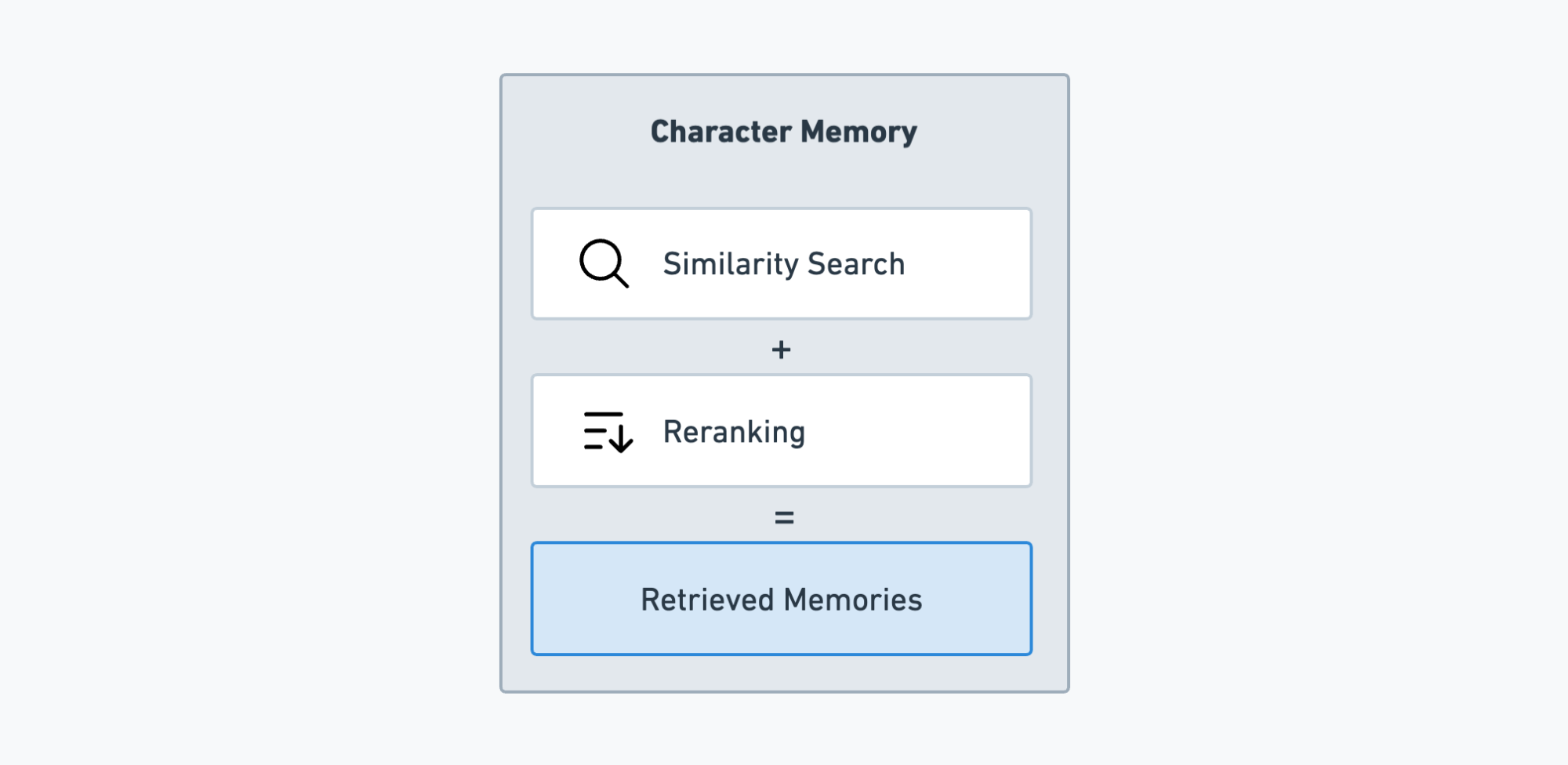
The character memory consists of multiple knowledge sources and is queried by doing multiple similarity searches and finally re-ranking the results. This setup makes it possible to quickly update the information the virtual characters have access to. Furthermore, by grounding the response generation in the retrieved memories, I was able to effectively combat hallucinations (factually inaccurate information) in the character responses.
Embedded in the character memory is a forgetting mechanism, strengthening often-used memories and continually weakening unused memories. The purpose of this system is to make the virtual characters appear more human-like.
Another interesting part of this project was the evaluation. With a lack of standard metrics for LLM-based systems in 2023, I had to come up with my own way of evaluating the system. I opted for a GPT-4 based evaluation to assess the number of hallucinations in the character responses. An automated fact-checking pipeline identifies verifiable claims and then individually compares them with the presented evidence (the memories), determining how supported the claims are:
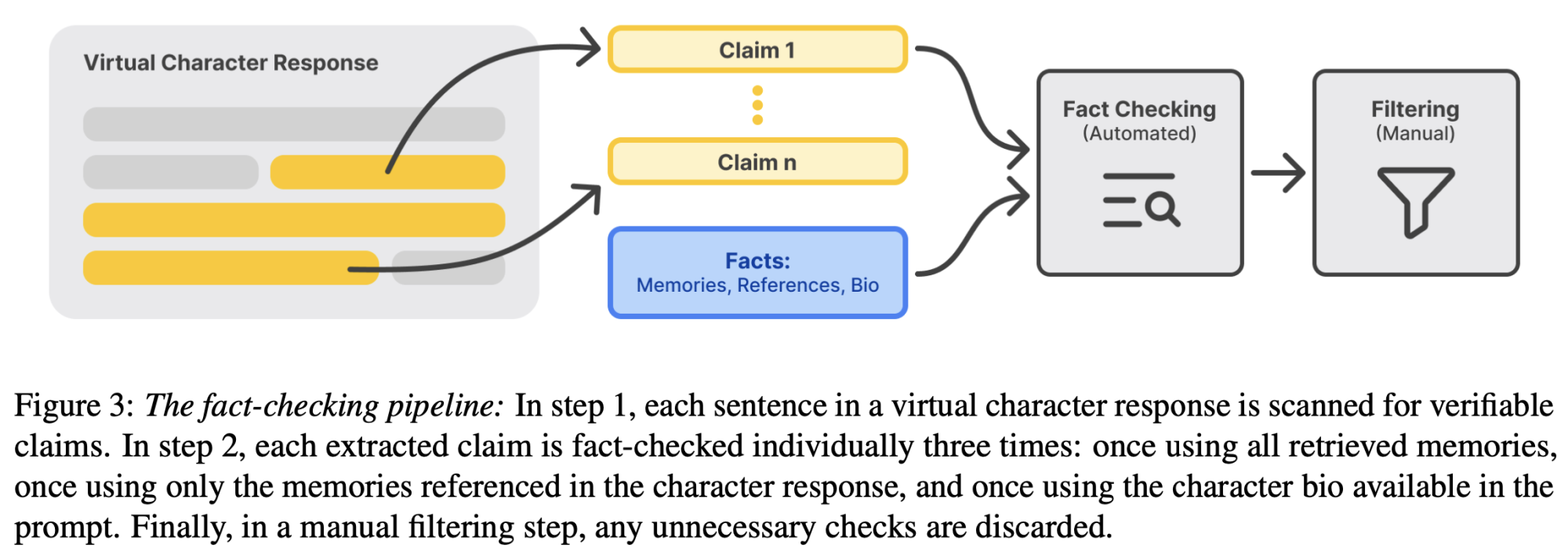
The paper explains the concepts above in a lot more detail. Please have a look if you are interested: Paper