
Overview
- When I studied abroad at the University of Edinburgh, I took a course that explored the history and present of Automatic Speech Recognition.
- In this course, we were tasked with creating a speech recognition system based on weighted finite-state transducers (WFSTs) and a Viterbi decoder.
- We created the speech recognition system using the library
openfst_pythonand worked on reducing the word error rate and increasing the computational efficiency of the algorithm. We did this by running various experiments:- Tuning transition probabilities, self-loop probabilities, and final probabilities.
- Testing different WFSTs, based on uni-gram or n-gram word occurrence probabilities and adding optional silences between words.
- Enhancing the Viterbi decoder by pruning the search-tree with different strategies.
- Improving the efficiency of the decoder by using a tree-structured lexicon with language model look-ahead.
- Through these experiments, we were able to increase the performance of the system drastically. Additionally, I now understand clearly how automatic speech recognition can work without neural networks. Such approaches are still used today, for example in low-resource environments.
Context
- 🗓️ Timeline: 01/2022 — 06/2022
- 🛠️ Project Type: Course project in Automatic Speech Recognition at the University of Edinburgh, UK
- 👥 Team size: 2
Technologies/Keywords
- Automatic Speech Recognition (ASR)
- Weighted Finite-State Transducers (WFSTs)
- Viterbi Decoder
- openfst_python Library
- Word Error Rate
- Computational Efficiency
- Transition Probabilities
- Self-Loop Probabilities
- Final Probabilities
- Uni-Gram Word Occurrence Probabilities
- N-Gram Word Occurrence Probabilities
- Optional Silences in Speech Recognition
- Pruning the Search-Tree in Decoders
- Tree-Structured Lexicon
- Language Model Look-Ahead
- Non-Neural Network Approaches in ASR
- State Machine Representation of Speech
- Deep Learning in Speech Recognition
Impressions
On a high level, speech can be represented as a state machine. Sound waves can be mapped to state transitions, making it possible to traverse through the state machine. Reaching a certain state can be understood as having recognized a certain word, e.g. “Peter”, as in the figure below:
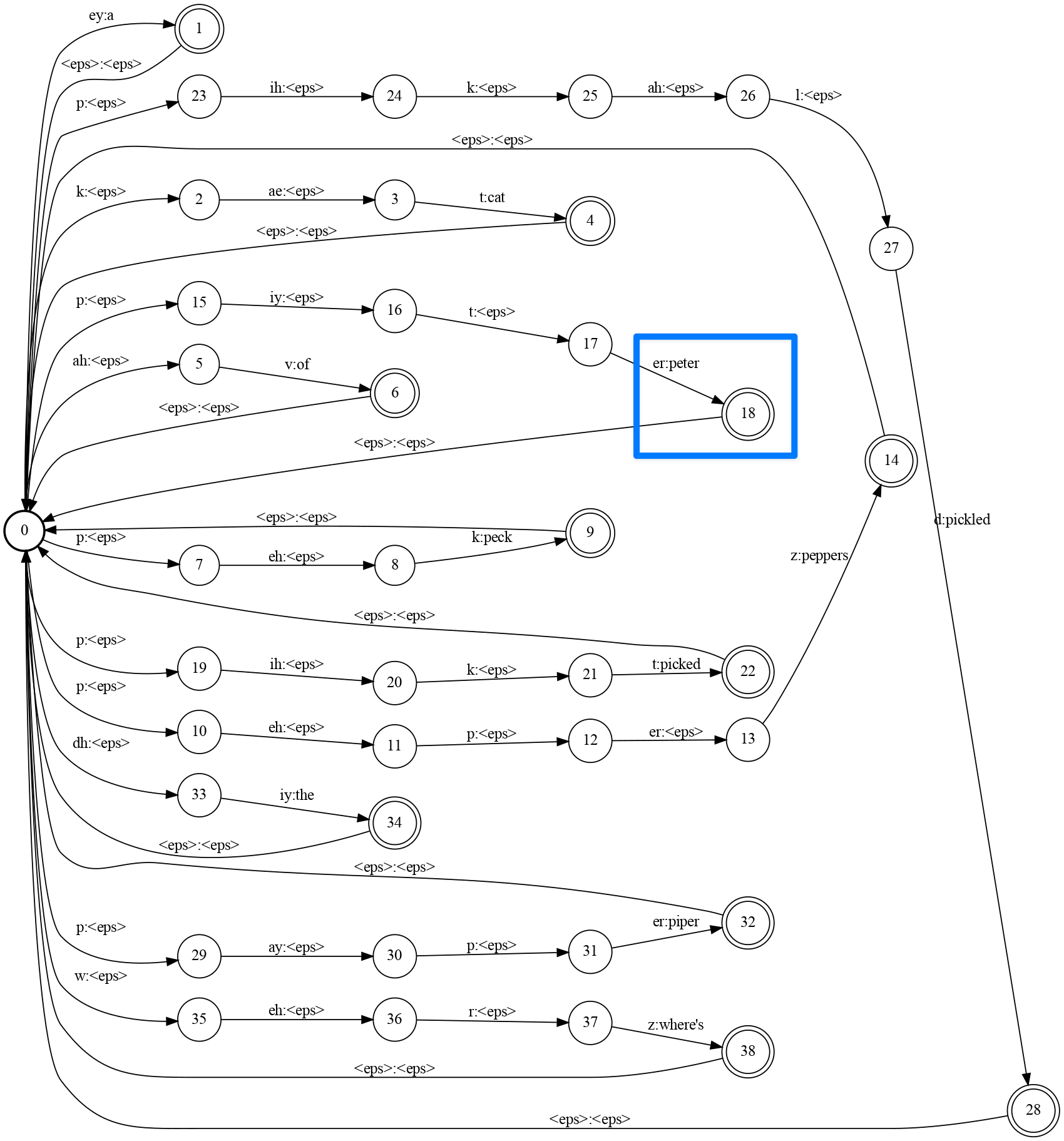
The problem with explicitly modeling states is that the size of the state machine quickly gets out of hand. There are ways of improving this situation, for example by merging multiple states into one, but the underlying problem remains. Today, almost all speech recognition systems rely on deep learning instead.



